Jina AI releases v5-omni: multimodal embeddings for text, images, video, and audio
Jina AI released jina-embeddings-v5-omni, a multimodal embedding model that maps text, images, video, and audio into a single vector space with support for nearly 100 languages.
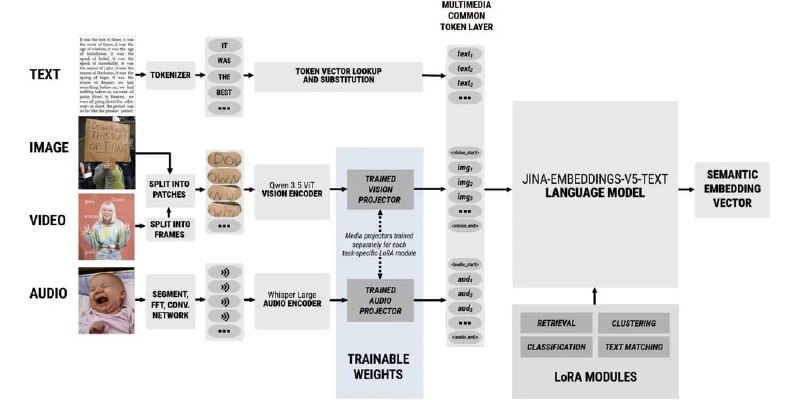
Jina AI released jina-embeddings-v5-omni this week, a multimodal embedding model that maps text, images, video, and audio into a single vector space. The model comes in two sizes: a 1.04-billion-parameter Nano variant with 8K context and a 1.74-billion-parameter Small variant with 32K context. Both versions support nearly 100 languages and maintain backward compatibility with the earlier jina-embeddings-v5-text model, meaning existing indexes don't need to be rebuilt.
The architecture is modular. Users can activate only the encoders they need—text, image, or audio—rather than loading the full multimodal stack. The model is available on HuggingFace and ModelScope, with a live demo hosted by Jina AI.