ConRetroBert reaches 75.4% accuracy on retrosynthesis by splitting retrieval and ranking
New arXiv preprint reframes template-based retrosynthesis as dense retrieval plus listwise ranking, using EMA-stabilized encoders to predict reactants from reaction templates without destabilizing hard-negative mining.
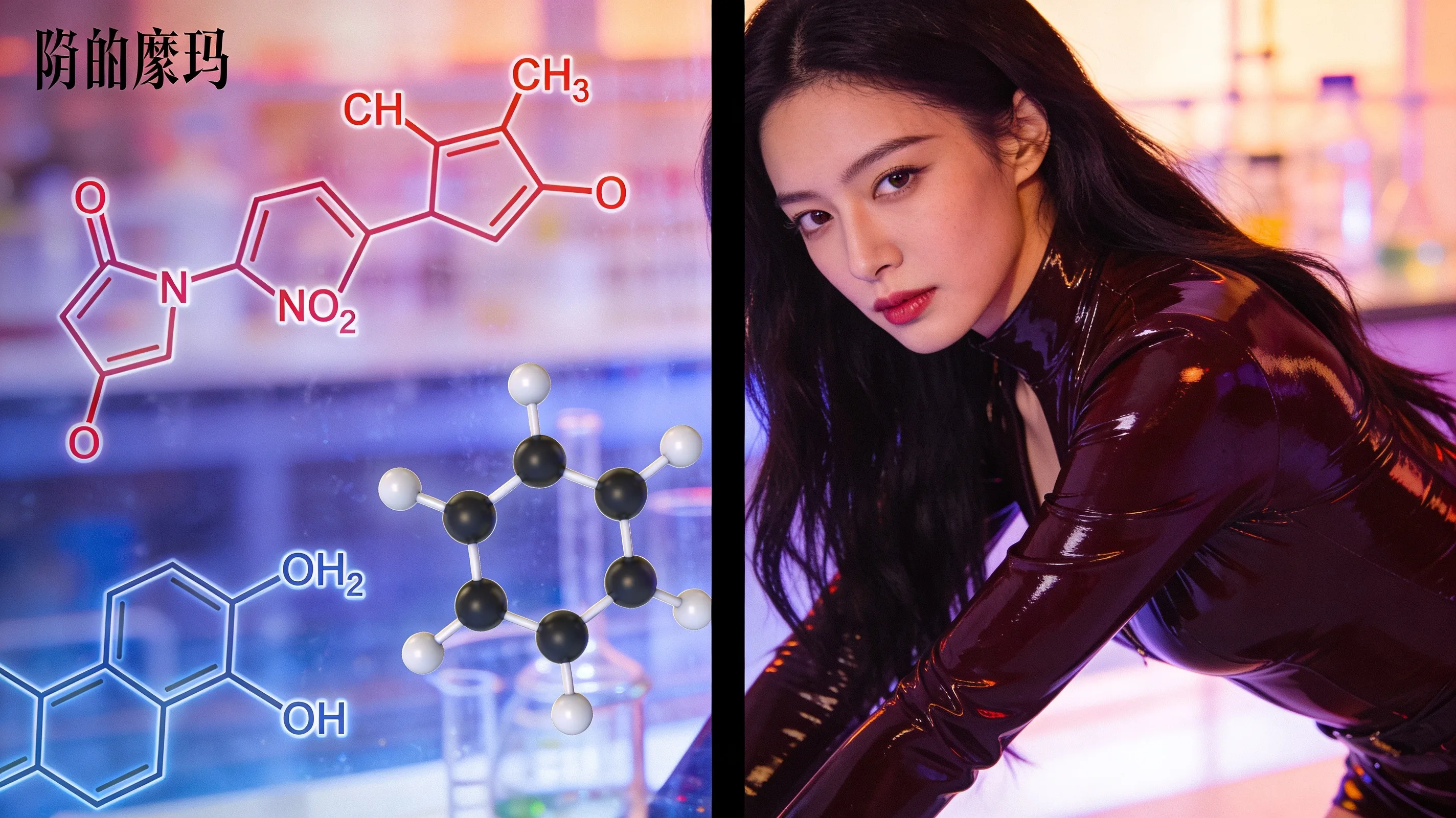
ConRetroBert, a dual-encoder framework presented in a new arXiv preprint, treats template-based retrosynthesis as a two-stage retrieval and ranking problem rather than global classification over thousands of reaction rules. The approach reports 75.4% top-1 accuracy on the USPTO-50k benchmark when fine-tuned from a leakage-controlled USPTO-Full checkpoint — a substantial jump over prior template-based methods that typically lag behind template-free models.
Template-based retrosynthesis predicts reactants by selecting an explicit reaction template from a library and applying it to the target product molecule. Each prediction is traceable to a known chemical transformation rule, which makes the approach valuable for synthesis planning. The catch has been that template libraries are long-tailed — a few rules appear frequently, thousands appear rarely — and framing template selection as a single softmax classification bottlenecks accuracy. ConRetroBert sidesteps this by splitting the task: Stage 1 uses contrastive pretraining to learn a shared embedding space between product molecules and reaction templates, then retrieves a small candidate set via dense similarity search. Stage 2 refines that candidate set with a listwise ranking objective that handles multiple valid templates per product.
On benchmarks
On USPTO-50k, Stage 2 candidate-set ranking alone lifts top-1 reaction accuracy from 50.5% to 61.3%. Adding the exponential moving average (EMA) template encoder — a slow-moving copy of the live encoder used to build the retrieval bank — pushes accuracy to 62.4% by stabilizing hard-negative mining during training. The EMA trick lets the live encoder adapt to ranking signals without invalidating the mined negatives, a common failure mode in dense retrieval systems. Fine-tuning from a USPTO-Full checkpoint (with leakage controls to prevent test-set contamination) reaches the reported 75.4% top-1 figure.
The authors note that retrieval-based template prediction is especially strong in the long tail of rare templates, and that many correct reactant predictions come from alternative valid templates rather than only the single recorded ground-truth label in the dataset. Code and data are available on GitHub.