Small models lose instruction-following after supervised fine-tuning on SlimOrca
A researcher's identical SFT recipe improved a 3B model's IFEval score by 2 points but degraded 1B and 2B variants by 5–6 points, raising questions about capacity thresholds for instruction tuning.
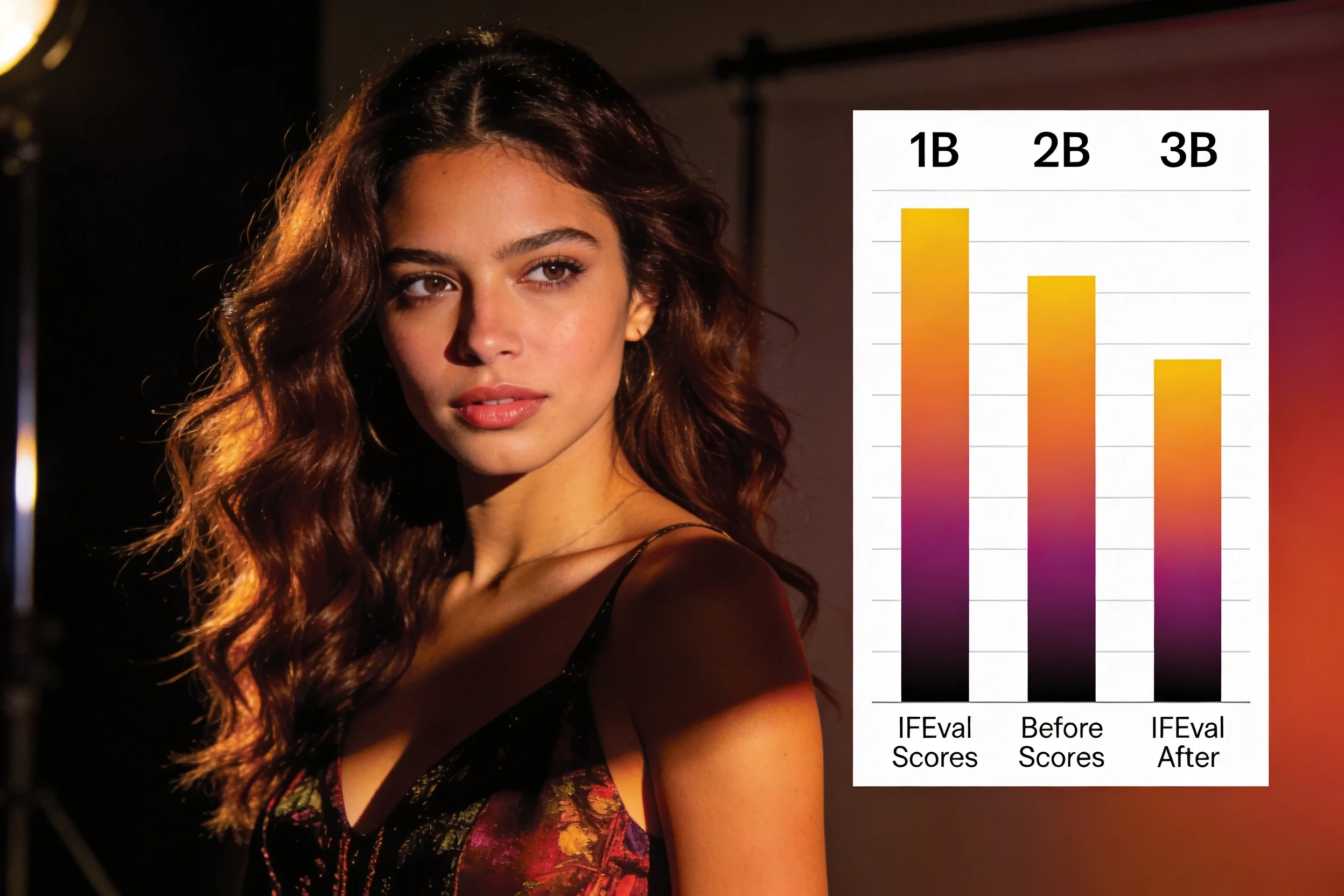
Supervised fine-tuning on SlimOrca degraded instruction-following performance in 1B and 2B parameter models while improving a 3B variant — a counterintuitive result that challenges assumptions about how small models respond to instruction datasets.
The experiment used identical training conditions across three model sizes: SlimOrca's 50,000-sample instruction dataset, LoRA rank 16, and one epoch. IFEval scores — a benchmark measuring adherence to explicit formatting and constraint instructions — dropped 5.75 points for the 1B model (from 20.50 to 14.75) and 4.91 points for the 2B (21.94 to 17.03). Only the 3B model improved, gaining 2.04 points to reach 25.18.
| Model | Base | After SFT | Delta |
|---|---|---|---|
| 1B | 20.50 | 14.75 | −5.75 |
| 2B | 21.94 | 17.03 | −4.91 |
| 3B | 23.14 | 25.18 | +2.04 |
The 3B run used a learning rate of 5e-5, while the smaller models trained at 2e-4. That difference leaves two plausible explanations: either the models below 3B lack the representational capacity to internalize instruction-following patterns without overwriting pre-existing capabilities, or the higher learning rate caused destructive updates that a gentler schedule would avoid.