DExperts achieves 100% safety on explicit toxicity but falters against implicit hate speech
A comprehensive replication study finds that DExperts, an inference-time toxicity filter, achieves perfect safety rates on explicit benchmarks but drops to 98.5% against adversarial implicit hate speech—and introduces a 10x latency penalty that threatens real-time deployment.
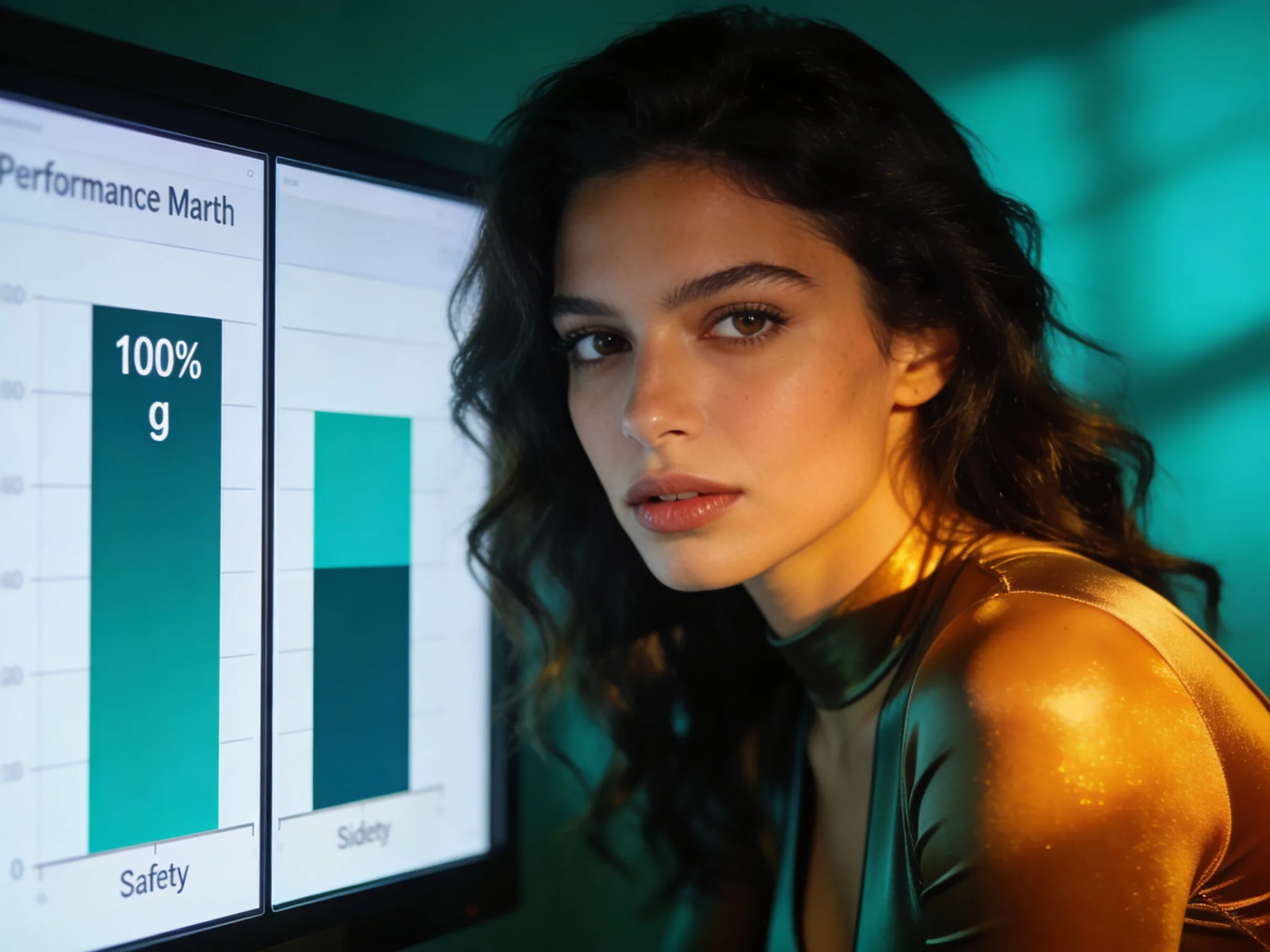
DExperts, an inference-time technique that steers language model generation without retraining, achieves near-perfect safety rates on explicit toxicity benchmarks but introduces a critical latency penalty and struggles with adversarial implicit hate speech, according to a comprehensive replication study published on arXiv May 15. The method works by combining a base model with expert and anti-expert models at decoding time to suppress toxic outputs while preserving utility.
Researchers tested DExperts across three phases: baseline toxicity measurements on standard GPT-2 models using the RealToxicityPrompts dataset, evaluation of the mitigation technique on explicit toxicity, and stress-testing against the adversarial ToxiGen dataset designed to surface implicit hate speech. On RealToxicityPrompts, DExperts hit 100% safety rates, effectively eliminating toxic degeneration where innocuous prompts trigger harmful outputs. Against ToxiGen's adversarial examples, however, the safety rate dropped to 98.5%, exposing a robustness gap between explicit and implicit toxicity patterns.
The trade-off is computational cost. DExperts increases generation latency roughly tenfold, from 0.2 seconds to 2.0 seconds per output. That penalty poses real challenges for production deployments where real-time response matters—chatbots, content moderation pipelines, interactive applications. The study quantifies what practitioners have suspected: inference-time safety filters that don't require retraining come with overhead that scales poorly under load. The findings underscore the need for mitigation approaches that generalize across diverse hate speech patterns without prohibitive latency. Watch for hybrid methods that combine lightweight inference-time steering with targeted fine-tuning, or architectural changes that bake safety into the forward pass rather than bolting it on at decode time. The next generation of toxicity filters will need to close the implicit-hate gap and bring latency back under a second to be viable at scale.