
Claude Opus 4.8 identifies as Qwen when prompted in Chinese
Claude Opus 4.8 responds to Chinese-language identity queries by identifying itself as Qwen, Alibaba's open-weight model, suggesting either training data leakage or an undisclosed fine-tuning choice.
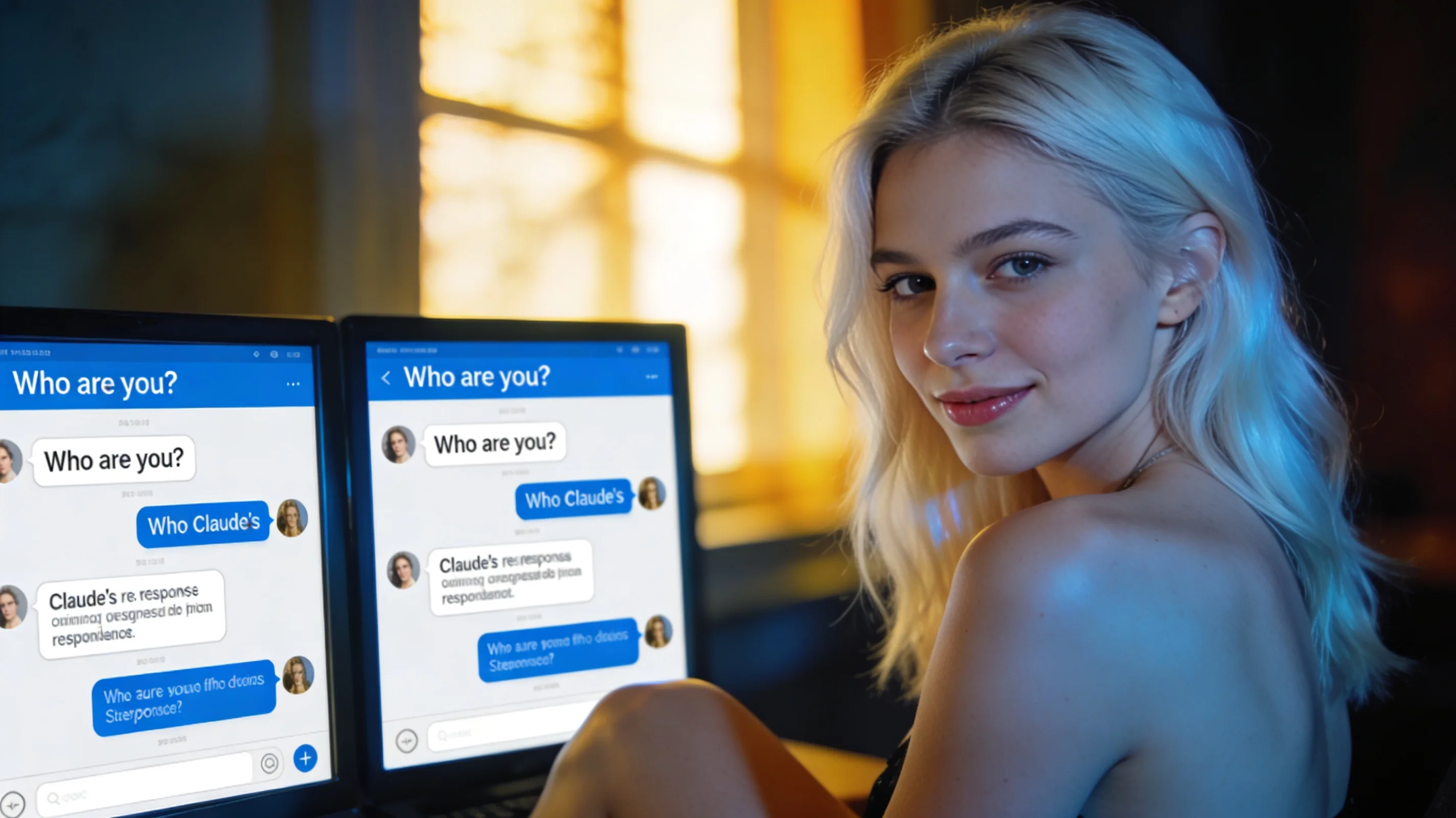
Claude Opus 4.8, Anthropic's latest flagship model, identifies itself as Qwen when prompted in Chinese—a behavior that has surfaced among AI practitioners testing multilingual model consistency this week. When asked about its identity in Mandarin, the model responds claiming Qwen lineage rather than Anthropic's Claude branding. The behavior appears limited to Chinese-language prompts; English-language identity queries return standard Claude responses.
The discrepancy points to either training data contamination from Qwen documentation or a deliberate fine-tuning choice Anthropic has not publicly disclosed. Anthropic's model cards for Opus releases make no mention of third-party model components or Qwen integration. If the model is genuinely incorporating Qwen training signals, it would mark an unusual convergence between a closed commercial API and an open-weight Chinese model family. Qwen 2.5 and its variants are widely adopted in Chinese-language applications, with training corpora publicly documented on HuggingFace and ModelScope.
The alternative explanation—that Opus 4.8's Chinese fine-tuning inadvertently learned to mimic Qwen's self-identification from web-scraped forum posts or documentation—would indicate a data-cleaning gap in Anthropic's pipeline. Anthropic has not yet commented on the behavior. Practitioners testing multilingual identity consistency should watch for similar aliasing in other non-English languages, and whether the next Opus point release patches the response or clarifies whether the training choice was deliberate.



