
ByteDance Bernini splits video generation into semantic planning and diffusion rendering
ByteDance's Bernini system uses a multimodal language model to plan scenes before a diffusion model renders them, built on WAN 2.2 weights with support for editing and object insertion.
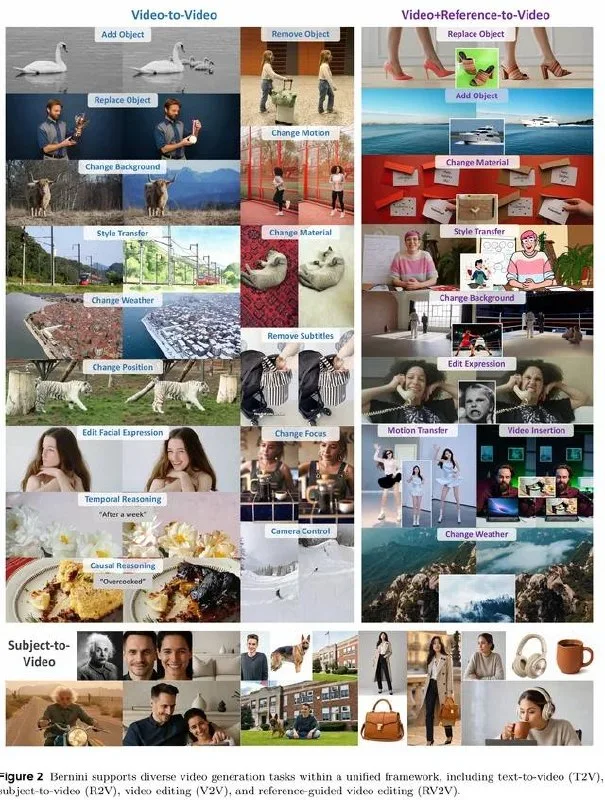
Bernini is a video generation and editing system from ByteDance that separates semantic planning from pixel rendering. A multimodal large language model first maps out the scene structure, then a diffusion model produces the final frames. The project builds on WAN 2.2 checkpoints and additional ByteDance weights, with capabilities spanning text-to-video generation, in-video editing, reference-driven synthesis, and object insertion into existing clips. The demo site went live this week at bernini-ai.github.io.
The two-stage architecture departs from end-to-end diffusion pipelines that handle prompt interpretation and pixel generation in one pass. By offloading semantic reasoning to a language model, Bernini can adjust scene composition or object placement without re-running the entire diffusion stack. The system accepts natural-language instructions for edits — swap a character, change lighting, insert a prop — and the MLLM updates the scene plan before the diffusion model re-renders affected frames.
WAN 2.2, ByteDance's open-weight video diffusion model released earlier this year, supplies the base generation weights. The Bernini repository lists additional fine-tuned checkpoints and auxiliary models for reference encoding and object masking, though ByteDance has not yet published training recipes or ablation studies. The demo interface shows multi-shot edits and reference-image conditioning, but compute requirements and inference latency remain undisclosed.
The next release should clarify whether the MLLM planning stage runs once per prompt or iteratively during generation, and whether the system supports real-time editing or requires full re-generation for each change. Open-weight practitioners will also want to know if the additional checkpoints will land on HuggingFace and what GPU memory footprint the two-model pipeline demands for local deployment.


