NVIDIA Nemotron 3 Ultra: 550B sparse model activates 55B weights for agent tasks
NVIDIA released Nemotron 3 Ultra, a 550-billion-parameter sparse model with 55 billion active weights, combining Mamba2 and Transformer layers for long-context agentic workflows.
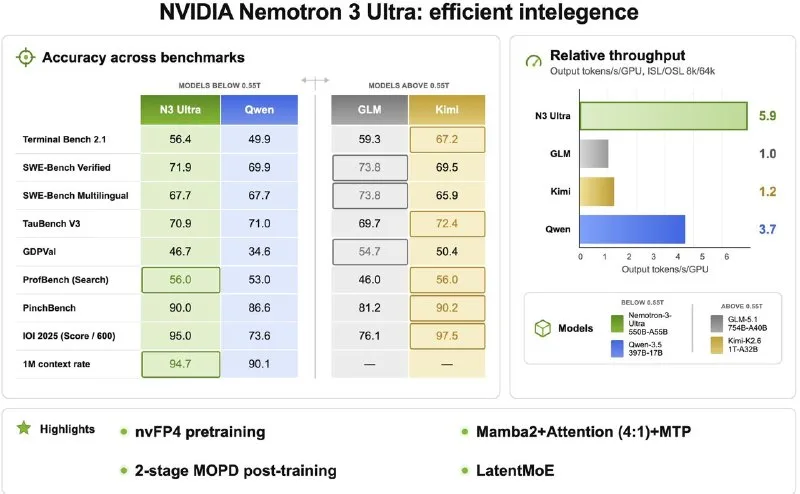
NVIDIA released Nemotron 3 Ultra, a 550-billion-parameter sparse mixture-of-experts model that activates 55 billion weights per forward pass. The architecture blends Mamba2 state-space layers and Transformer blocks in a 4:1 ratio, pretrained on 20 trillion tokens in NVFP4 precision and post-trained with a two-stage MOPD pipeline. The model natively supports multi-turn planning and ships with base weights, post-trained checkpoints, reward models, NVFP4-quantized versions, and full training recipes under an open license.
The LatentMoE design keeps inference costs manageable despite the 550B total parameter count — only 55B are active at runtime, putting compute closer to a dense 70B model while preserving the capacity advantages of a much larger expert pool. The 4:1 Mamba2-to-Transformer ratio reflects a broader industry bet on state-space models for long-context efficiency: Mamba layers scale subquadratically with sequence length, while Transformer blocks preserve the attention mechanisms that excel at tool-use reasoning. NVIDIA published the weights on HuggingFace in BF16 and NVFP4 formats, with community GGUF quantizations already available from Unsloth for CPU and lower-VRAM inference. Free API access is live on Opencode for testing multi-step agentic tasks without local hardware.




