MisoTTS 8B clones voices in 110ms with 10-second audio samples
Miso Labs released MisoTTS 8B, an open-source text-to-speech model that clones voices from brief audio clips and generates conversational speech near real-time.
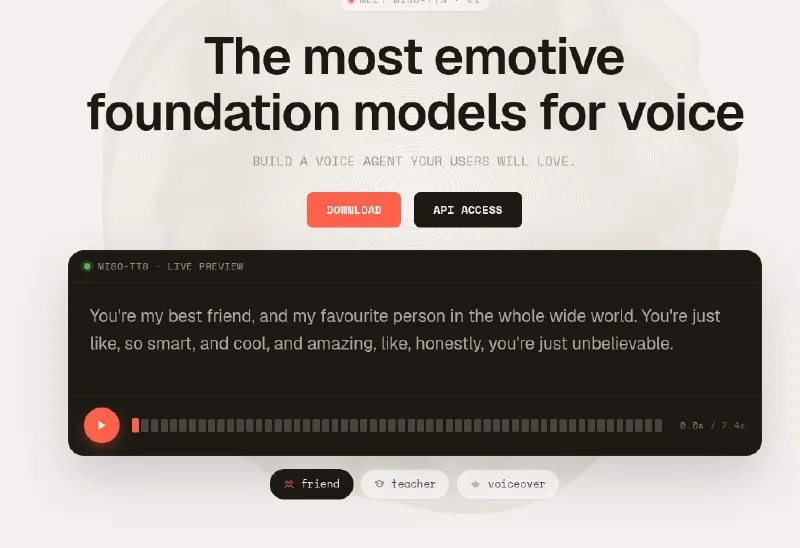
MisoTTS 8B, a new open-source text-to-speech model from Miso Labs, clones voices from a 10-second audio sample and maintains speaker identity across full conversations. The model responds in 110 milliseconds, approaching real-time performance for conversational AI applications. Weights are available on HuggingFace alongside a live demo Space and GitHub repository with inference code.
The architecture pairs a Llama 8B base model—built in the style of Llama 3.2—with a Llama 300M audio decoder. That two-stage design separates text understanding from audio synthesis, a pattern that has become common in recent open-weight TTS releases. The 8B parameter count puts MisoTTS in the same weight class as other conversational models optimized for edge deployment, though Miso Labs has not yet published GPU memory requirements or throughput benchmarks beyond the 110ms latency figure.
Voice cloning from short samples has been a competitive frontier in open-source TTS. Earlier models often required minutes of training audio or struggled to preserve speaker characteristics across longer outputs. MisoTTS's 10-second requirement and claimed identity preservation across full conversations suggest the model is targeting real-time dialogue systems—chatbots, voice assistants, interactive agents—rather than audiobook narration or long-form content generation. The model currently supports English only.
The HuggingFace Space lets users upload a reference audio clip and type text for the cloned voice to speak, offering a quick test of voice fidelity and latency. The GitHub repository includes setup instructions and inference scripts for local deployment.




