q0 framework trades compute for data via parallel ensembles and cyclic schedules
New pretraining framework runs parallel model ensembles with anti-phase learning-rate and weight-decay cycles, then distills and weights predictions to squeeze 12.9× more value from fixed datasets when compute is abundant but training tokens are scarce.
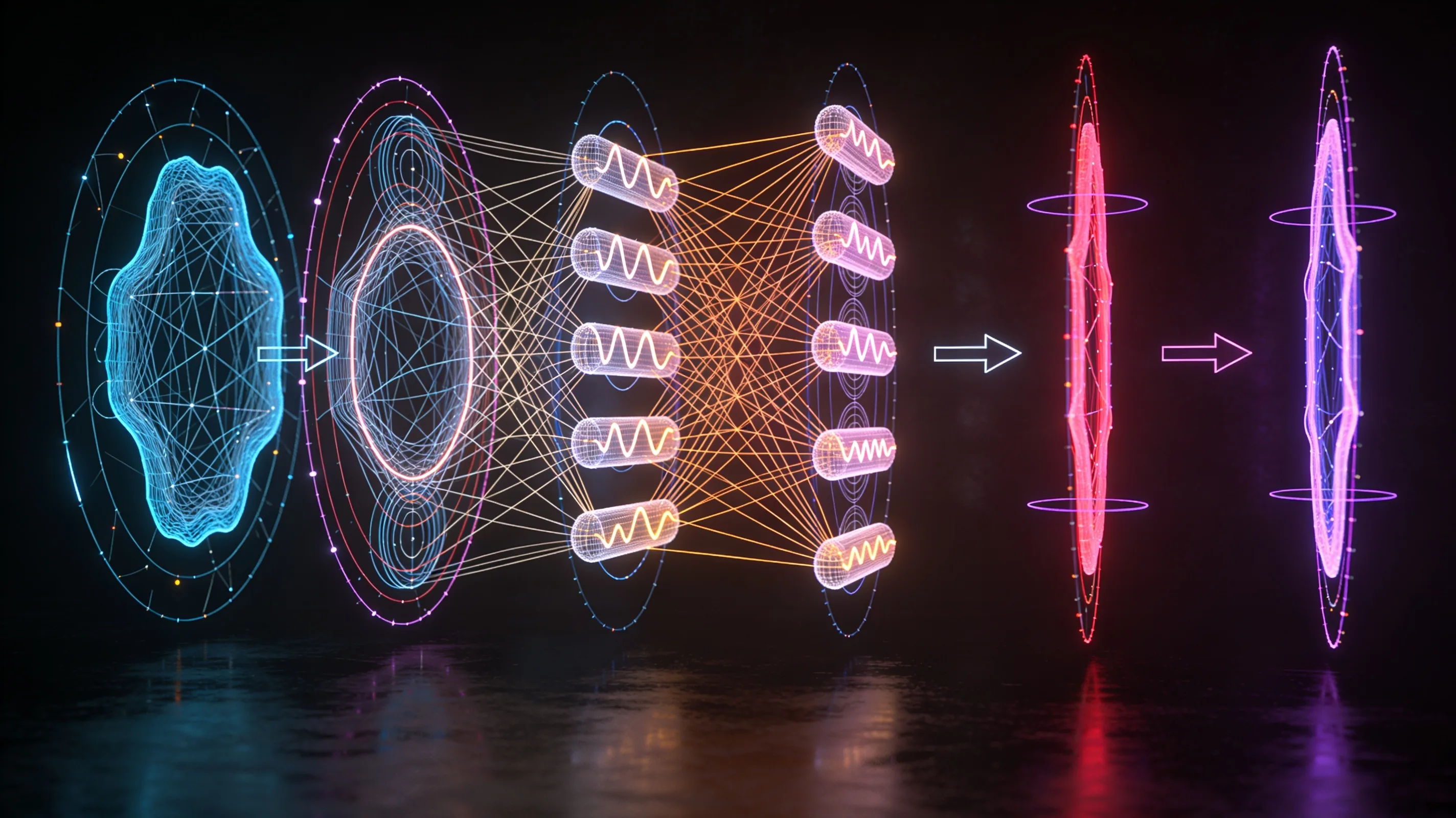
A team at QLabs has released q0, a pretraining framework that squeezes up to 12.9 times more value from a fixed dataset by training many models in parallel rather than running one network through endless epochs. The approach—detailed in an arXiv preprint released June 5—combines cyclic learning-rate and weight-decay schedules, sequential distillation across model checkpoints, and ensemble inference to sidestep the saturation plateau that kills most multi-epoch training runs.
The core insight is straightforward: once a single model has seen the same data twice, returns diminish fast. q0 instead spins up a pool of models that explore different regions of the hypothesis space, then distills knowledge forward through the pool and weights their predictions at inference time using a learned "generalization prior." The result is a 16× improvement on downstream benchmarks when compute is plentiful but training tokens are scarce.
One standout technique is the anti-phase cycling of learning rate and weight decay—high learning rate for exploration, high weight decay for generalization, flipped every few thousand steps. The authors call it a "hyper-epoch" schedule. It's dead simple and, according to the paper, surprisingly effective at keeping models from collapsing into the same local minimum.
For practitioners sitting on spare GPU cycles but limited domain data—medical corpora, low-resource languages, proprietary logs—q0 offers a concrete recipe: parallelize training, chain the checkpoints through distillation, and ensemble at inference. The trade-off is higher serving cost (you're running multiple models or a distilled ensemble), but the data savings can be existential when high-quality pretraining tokens are running out.
The preprint is available at arxiv.org/abs/2606.03938, and the code repository is at github.com/qlabs-eng/slowrun.




