
Kimi K2.7 Code cuts token use 30% with trillion-parameter MoE and vision
Moonshot AI released Kimi K2.7 Code, a trillion-parameter mixture-of-experts model that activates 32 billion parameters per token, cuts token usage by 30 percent over K2.6, and adds multimodal vision support via MoonViT encoder.
Moonshot AI released Kimi K2.7 Code this week, a trillion-parameter mixture-of-experts model that activates 32 billion parameters per token. The model handles Rust, Go, and Python, processes images and video through a MoonViT vision encoder, and operates in permanent thinking mode across a 256,000-token context window. Weights are available on HuggingFace under a modified MIT license.
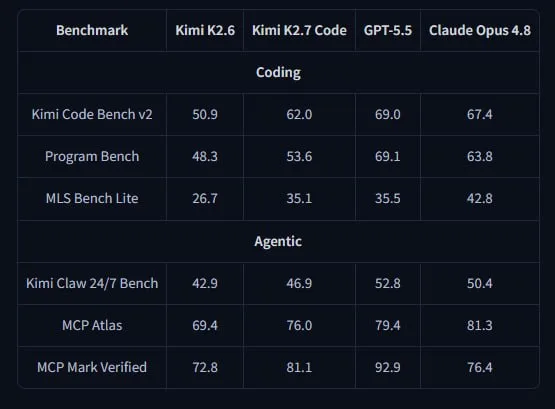
The model outperforms K2.6 on coding tasks while consuming 30 percent fewer tokens per operation. It supports multi-step agentic workflows—debugging, tool use across multiple steps, and long-session coding tasks that demand sustained context. The vision encoder lets it parse screenshots, diagrams, and video frames alongside code, a capability K2.6 lacked. Moonshot has not opened chat-based access to the base model; the Kimi Code interface requires a subscription, and API access is listed but not yet live.
The company has not published benchmark tables comparing K2.7 to GPT-4, Claude 3.5 Sonnet, or other frontier code models, so practitioners will need to run their own evals on the open weights to gauge real-world performance against closed alternatives. At 32 billion active parameters, K2.7 Code sits at the edge of what consumer hardware can run without quantization—the next release should ideally ship a smaller distilled variant for local deployment, clarify API pricing, and publish head-to-head benchmark numbers.



