
Liquid AI releases LFM2.5-8B-A1B: 253 tokens/sec on M5 Max, 128K context
Liquid AI's newest 8B-parameter MoE model runs at 253 tokens/sec on Apple M5 Max and 30 tokens/sec on smartphones, with context expanded to 128K tokens and a doubled tokenizer vocabulary.
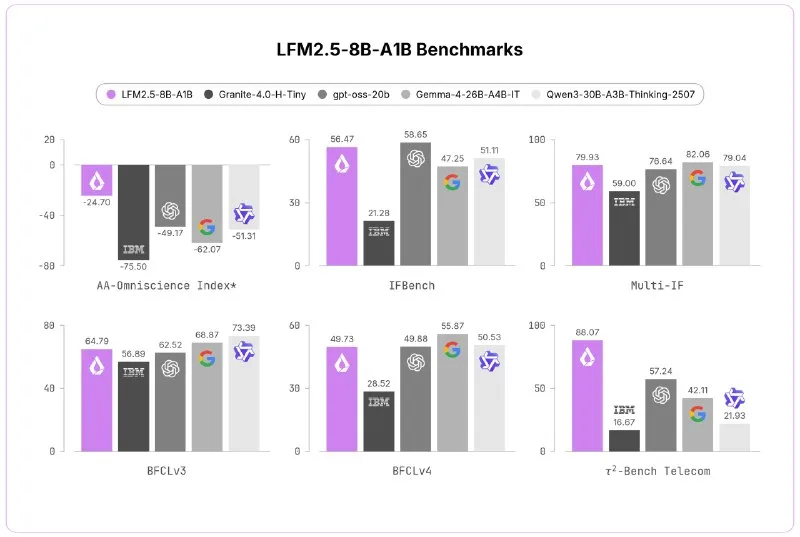
LFM2.5-8B-A1B, Liquid AI's 8-billion-parameter mixture-of-experts model, activates just 1 billion parameters per forward pass and reaches 253 tokens per second on Apple M5 Max hardware in 6 GB of memory—around 30 tokens per second on smartphones. Released this week, the model expands context from 32,000 to 128,000 tokens and triples pretraining data from 12 trillion to 38 trillion tokens with large-scale reinforcement learning. The tokenizer vocabulary doubled from 65,500 to 128,000 units, improving non-Latin script handling by roughly 6 percent for Russian.
Liquid AI claims LFM2.5-8B-A1B matches larger checkpoints like Gemma-4-26B on instruction-following and agentic tasks while keeping active parameters at 1 billion. The checkpoint ships with llama.cpp, MLX, vLLM, SGLang, and ONNX Runtime support. Weights are published under the LFM Open License, which permits commercial use with attribution. A browser playground is live on the HuggingFace model card.




