
Supervised Memory Training lets RNNs learn in parallel without backprop through time
Akarsh Kumar and Phillip Isola propose Supervised Memory Training, a two-stage method that uses a Transformer teacher to compress history into memory states, then distills those into an RNN student—eliminating sequential backprop and gradient instability.
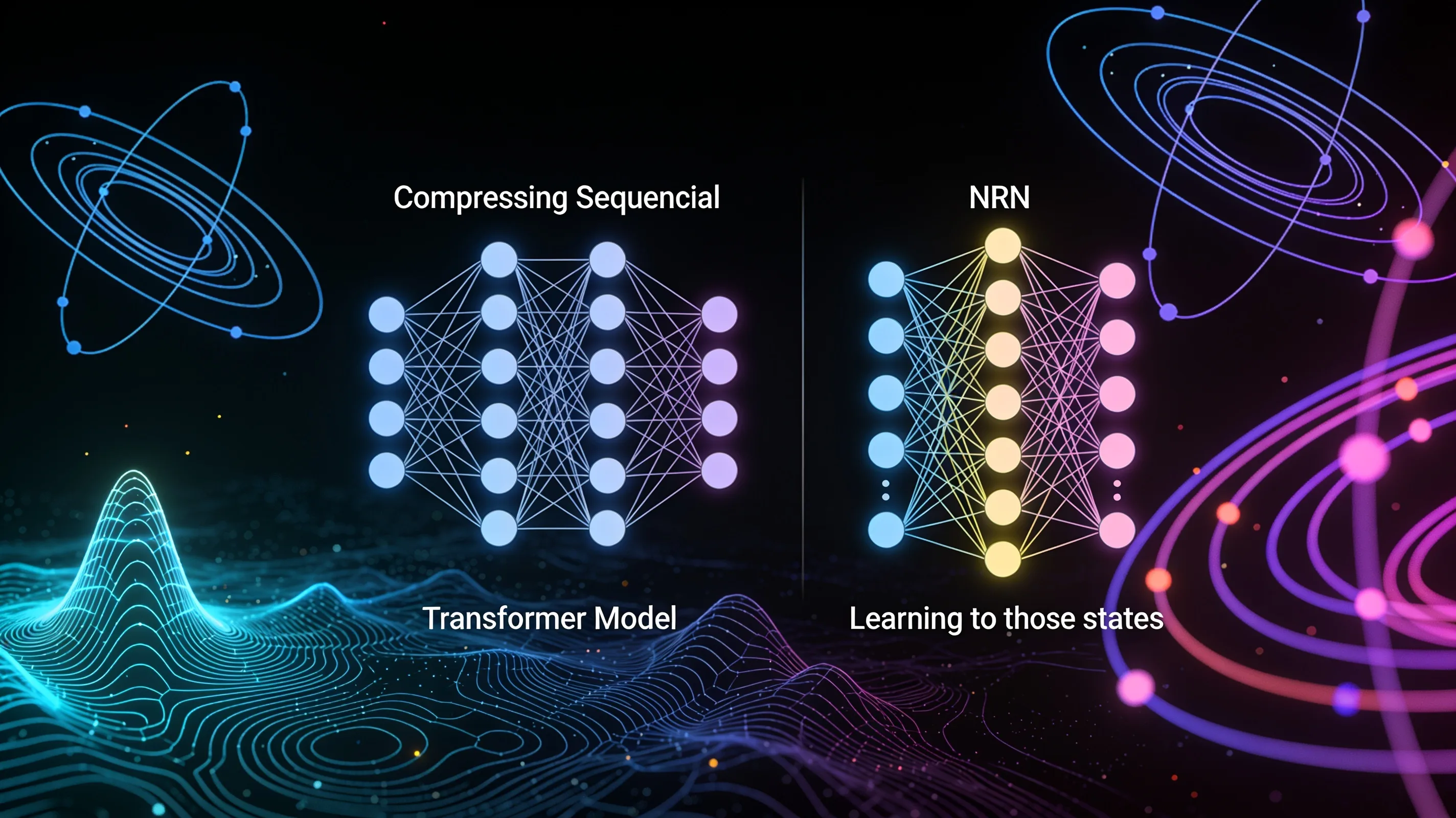
Supervised Memory Training (SMT), introduced by researchers Akarsh Kumar and Phillip Isola, sidesteps the sequential bottleneck that has historically plagued recurrent neural networks. The method trains a Transformer to learn compressed memory states holding enough information to predict the next token, then uses those states as supervision targets for a nonlinear RNN. Because the RNN learns to predict the next memory state in a single forward step, training parallelizes fully across time with a gradient path of O(1) depth—no backpropagation through time, no exploding or vanishing gradients.
The approach decouples representation learning (what to remember) from transition dynamics (how to update memory), letting practitioners pretrain expressive nonlinear RNNs on long sequences without the instability that has plagued recurrent architectures. At inference the RNN runs in constant O(1) memory per step, preserving efficiency on very long contexts where Transformers falter. The authors also introduce DAgger Memory Training (DMT), an iterative refinement that mixes teacher and student memory states during training. Code is available at github.com/akarshkumar0101/smt; the preprint was posted to arXiv on June 17, 2026 as arxiv.org/abs/2606.06479.



