
DeepSeek chat adds beta vision mode for image understanding
DeepSeek's chat interface now includes a beta vision feature that interprets full images, not just text extraction, expanding the platform's multimodal capabilities.
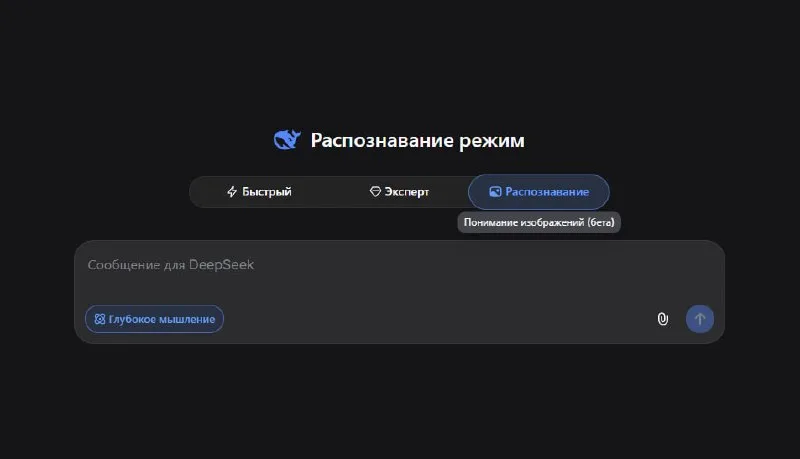
DeepSeek rolled out a beta vision mode in its chat interface this week, adding image understanding to the platform. The feature goes beyond optical character recognition—it interprets the full content of uploaded images. Users can now upload photos, diagrams, or screenshots and ask questions about their content, with the model analyzing visual elements alongside any embedded text.
The update positions DeepSeek's chat as a multimodal interface, joining the wave of vision-language models that handle both text and image inputs in a single conversation thread. DeepSeek has not disclosed which underlying model powers the vision capability or whether it runs on the same architecture as the company's text-only chat backend. The beta label suggests the feature is still under active development, with accuracy and edge-case handling likely improving over the coming weeks.
The next question is how fast DeepSeek iterates on the vision stack—whether it adds video understanding, PDF parsing with layout awareness, or multi-image comparison in follow-up releases. For now, the beta gives early users a look at where the platform's multimodal roadmap is headed.



