
Alignment methods converge on metrics but diverge in weight space
A new HuggingFace Space compares SFT, RFT, DFT, offline GRPO, DPO, and DAPO on identical data and finds all reach similar metrics, but DPO-family methods learn fundamentally different parameter configurations than supervised approaches.
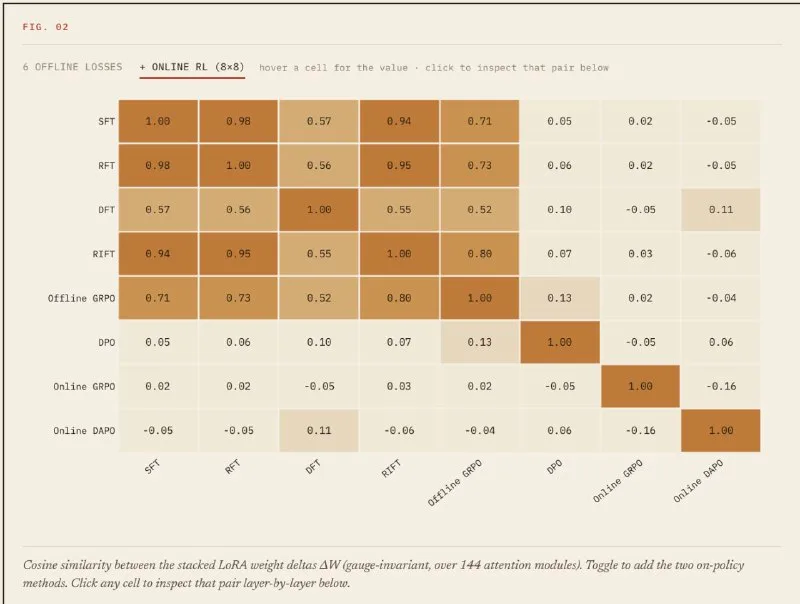
A new interactive comparison on HuggingFace Spaces shows that six popular preference alignment methods produce nearly identical metrics but learn strikingly different weight landscapes. Researcher Alex Wortega trained models using supervised fine-tuning (SFT), rejection fine-tuning (RFT), direct fine-tuning (DFT), offline GRPO, DPO, and DAPO—a GRPO variant—on the same dataset and measured both benchmark convergence and parameter geometry.
All methods hit similar scores, but weight analysis revealed a sharp divide. SFT, RFT, DFT, and offline GRPO learned roughly the same parameter structure, clustering together in weight space. DPO, online GRPO, and DAPO each learned distinct configurations that differed from one another and from the supervised cluster. The divergence held across learning rates and random seeds, suggesting the split is intrinsic to the optimization objective rather than a training artifact.
For practitioners, the implication is clear: two methods hitting the same MMLU or MT-Bench score may generalize differently on out-of-distribution prompts or respond differently to further fine-tuning. The supervised methods appear to converge on a shared solution space, while the preference-optimization family each carves out distinct regions of the loss landscape. The consistency across hyperparameters strengthens the case that loss function, not training noise, drives weight geometry. The HuggingFace Space visualizes the parameter space interactively.



