
GLM-5.2 outperforms Opus 4.8 on coding, wins Design Arena benchmark
Z.ai's GLM-5.2 open-weight model outscores Anthropic's Opus 4.8 on coding benchmarks and claims first place on Design Arena, with MIT-licensed weights and million-token context.
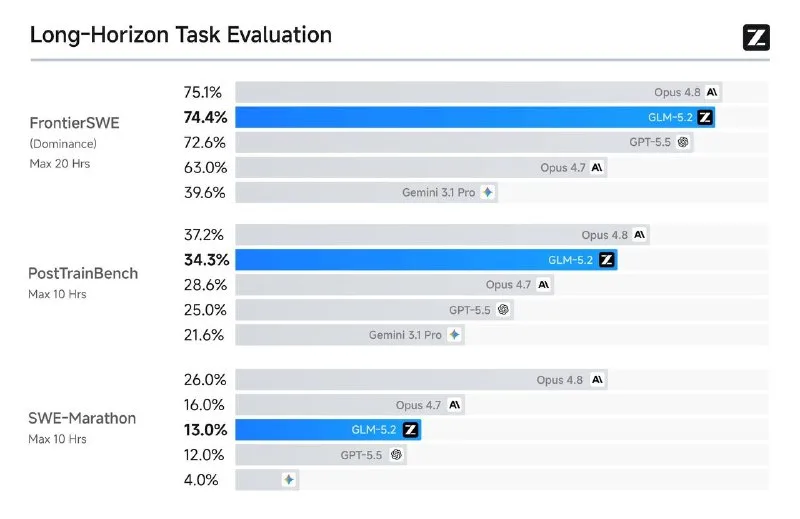
GLM-5.2, an open-weight large language model from Z.ai, has beaten Claude Opus 4.8 on coding benchmarks and taken first place on Design Arena ahead of Claude Fable 5. The model ships with a million-token context window and handles long multi-step tasks. Z.ai published the weights under an MIT license, making it one of the most permissive releases in the 100B+ parameter class.
Design Arena evaluates models on visual reasoning and creative problem-solving tasks—a category where closed frontier models have historically dominated. Running the model locally requires eight H100 GPUs, but Z.ai offers API access at a lower price point than most frontier models, and a chat interface at chat.z.ai requires a GLM Coding Plan subscription. The MIT license removes most deployment restrictions, allowing commercial use without additional agreements. The million-token context window ranks among the largest available in an open-weight model today.



