
Bowtie-Former cuts pretraining FLOPs 22% by narrowing middle layers
Researchers propose a decoder-only transformer that narrows the hidden dimension in middle layers while keeping input and output layers wide, reducing compute and KV cache costs without adding projection parameters.
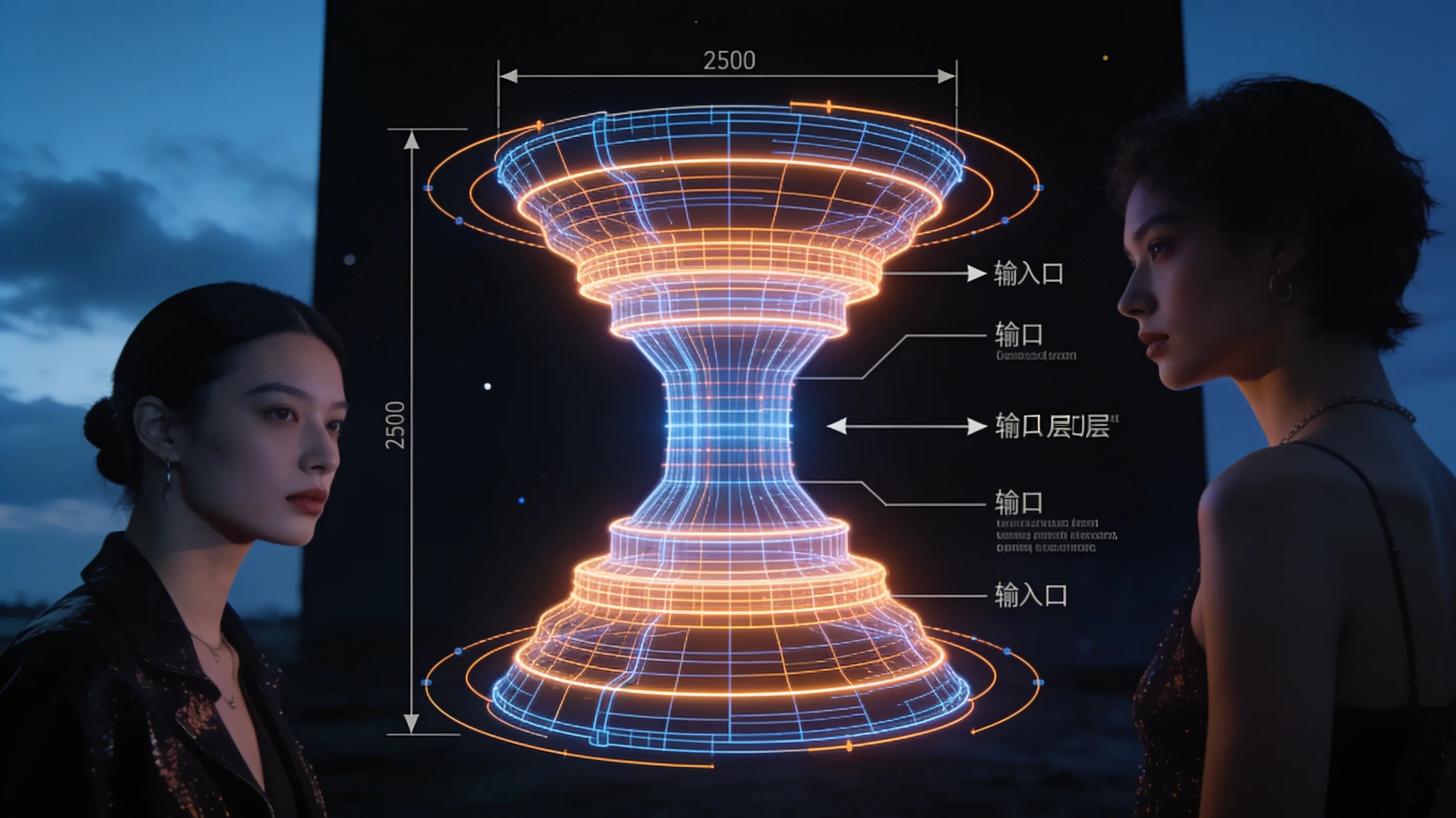
A new decoder-only transformer architecture narrows the hidden dimension in middle layers while keeping early and late layers wide, cutting pretraining compute by up to 22 percent in FLOPs and shrinking KV cache and I/O overhead by 15 percent at inference. The design, called bowtie-former, was described in a preprint released this week by researchers including Zhaofeng Wu, Oliver Sieberling, Shawn Tan, Rameswar Panda, Yury Polyanskiy, and Yoon Kim. Reference code is available on GitHub.
Most transformers hold hidden dimension constant across all layers. Bowtie-former instead implements a bowtie or hourglass capacity profile: early and late layers remain wide, while middle layers compress. The architecture uses a parameter-free carry-forward mechanism that copies inactive coordinates through the residual stream, eliminating the need for learned projection layers when dimension changes. The authors argue this physical narrowing acts as a structural regularizer, preventing representation collapse in the middle of the network and balancing activation load.
What stands out
- 01No projection overhead. Dimension changes happen via carry-forward—inactive channels are simply copied forward through the residual stream. No extra weight matrices, no learned projections.
- 0222% FLOPs reduction. Empirical results show pretraining compute drops by up to 22 percent compared to same-parameter-count constant-width transformers, with downstream task quality consistently higher.
- 0315% smaller KV cache. Inference memory and I/O costs fall 15 percent because middle layers store fewer key-value pairs. The savings compound in long-context scenarios.
- 04Compression valleys. The paper identifies "compression valleys" in middle layers—zones where representations risk collapsing. Physical narrowing forces the model to compress information structurally, preventing the collapse.



