
Qwopus 3.6-27B-v2 lands in fp8 and GGUF quantizations
The second iteration of the Qwopus assistant model is now available in fp8 and GGUF quantizations, targeting local deployment at reduced precision.
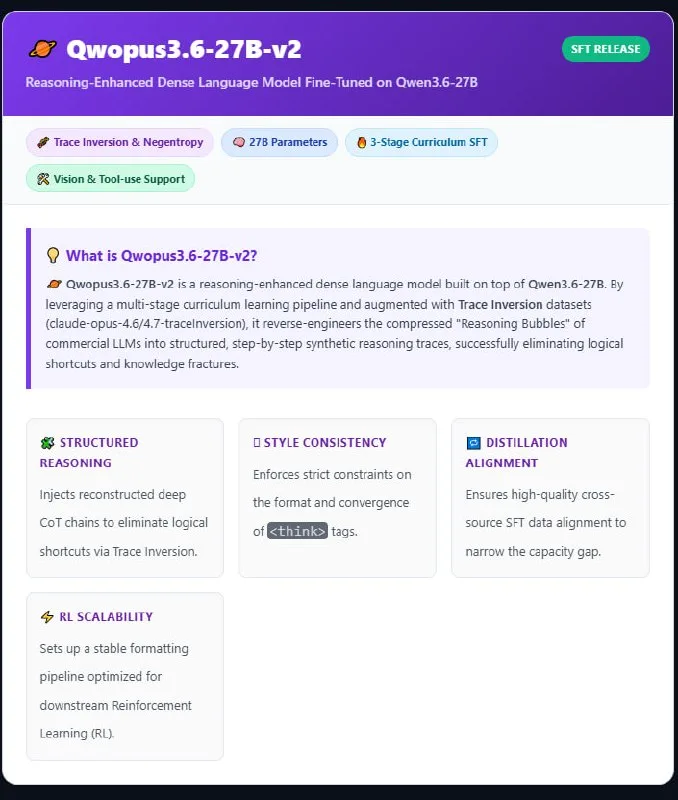
Qwopus 3.6-27B-v2, a 27-billion-parameter assistant model, is now available in fp8 and GGUF quantizations for local inference. The release marks the second version of the Qwopus line, though architectural details and changes from v1 remain undisclosed. Both quantization options target practitioners running inference on consumer hardware; fp8 cuts memory footprint roughly in half compared to full-precision weights, while GGUF support unlocks llama.cpp and Ollama workflows.
The model carries an assistant tag, suggesting fine-tuning for conversational and instruction-following tasks. No benchmark scores, context length, base-model lineage, or license information appear in the release materials. That absence leaves open questions about how it stacks against other 27B open-weight assistants like Qwen 2.5-27B-Instruct or Llama 3.3-27B variants. The fp8 quantization is a standard choice for balancing speed and quality on mid-range GPUs.
The sparse release details—no training documentation, no evaluation data, no explicit license—make it difficult to assess whether Qwopus 3.6-v2 represents a meaningful step forward or a lateral move in the crowded 27B assistant space. Practitioners considering a download will want to see training details, benchmark comparisons, and a clear license statement in the next iteration.



