
Terminal Bench releases data-curation pipeline for open-weight agentic training
A new preprint from Terminal Bench describes a data-mixing and filtering strategy for agentic model training, though experiments used Qwen 3 32B before Qwen 3.5 arrived.
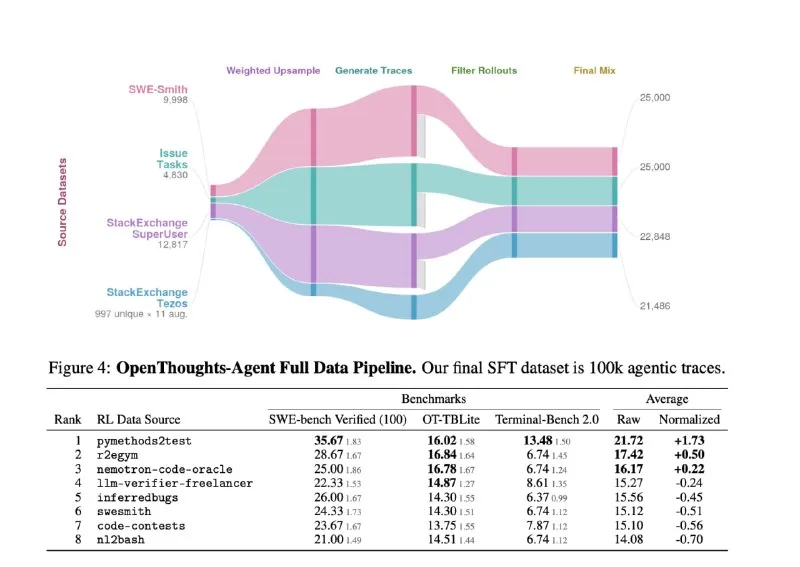
Terminal Bench has released a preprint outlining a straightforward pipeline for training agentic models: assemble diverse task-specific datasets, apply quality filters, then fine-tune a large open-weight foundation model.
The team chose Qwen 3 32B as the training target, a choice that reflects the model's popularity in the open-source community when experiments began. The paper does not benchmark against Qwen 3.5, which shipped after the work wrapped. That timing gap means the headline numbers may already look dated to practitioners tracking the latest Qwen checkpoints.
Terminal Bench has built a reputation for practical agentic evaluations, and the new work extends that focus upstream into training data. The recipe itself emphasizes data quality over volume—a philosophy that aligns with recent trends in open-weight training where smaller, cleaner datasets often outperform larger, noisier corpora. No exotic techniques appear; instead, the authors stress disciplined curation and compute allocation.
Qwen 3.5 brought architectural improvements and expanded context windows that make direct comparisons tricky. Practitioners looking to replicate the Terminal Bench approach will need to decide whether to stick with the Qwen 3 baseline the paper used or port the recipe to newer checkpoints. For teams building agentic systems on open weights, the paper offers a useful template: curate task-specific data, filter aggressively, train on a capable base model. The fact that the work landed between Qwen releases does not invalidate the method, but readers should treat the benchmark tables as a snapshot of mid-2026 rather than a current state-of-the-art claim.



