
Qwen3-ForcedAligner-0.6B timestamps speech across 11 languages with non-autoregressive alignment
Alibaba's new 600M-parameter forced-alignment model timestamps speech at word granularity in 11 languages, including Russian, outperforming end-to-end aligners on accuracy.
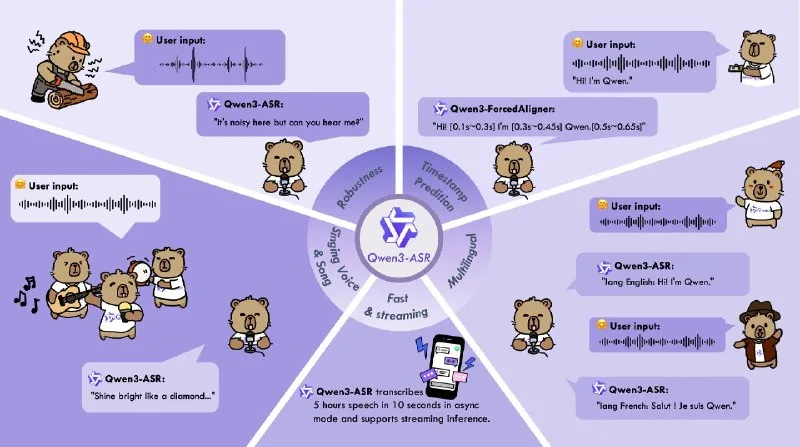
Qwen3-ForcedAligner-0.6B is a 600-million-parameter forced-alignment model from Alibaba that timestamps speech at the word level across 11 languages, including Russian. Unlike autoregressive ASR systems that generate transcripts token by token, this model operates non-autoregressively — it predicts all word boundaries in a single forward pass, beating end-to-end alignment architectures on accuracy benchmarks. Forced alignment is the task of mapping a known transcript back onto an audio waveform to extract precise start and end times for each word, a step used in subtitle generation, dataset labeling, and pronunciation scoring.
The weights are available on HuggingFace under an Apache 2.0 license. Built on the Qwen3 language-model backbone and fine-tuned specifically for alignment rather than open-ended transcription, the model runs efficiently on consumer hardware — a single GPU with 8 GB VRAM is sufficient for real-time inference on typical audio files. Released this week with no separate technical paper, implementation details and evaluation tables are documented in the HuggingFace model card.



