Distilling from full reasoning chains preserves model capability; summaries fail
A new preprint shows that distilling from complete reasoning traces preserves downstream capability, while distilling from summarized outputs fails to transfer the underlying skill.
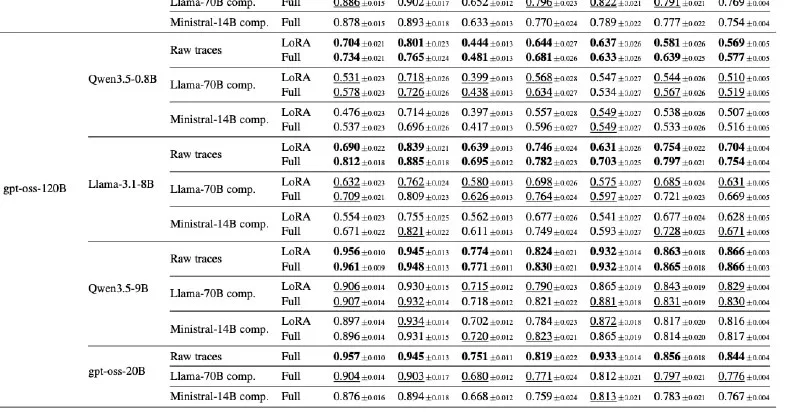
A preprint posted to arXiv this week argues that distillation works only when the student model learns from the teacher's full reasoning chain — not from a condensed summary of the final answer. The paper tests whether a smaller model can inherit a capability by training on either complete step-by-step traces or on abridged versions that skip intermediate logic.
The authors ran experiments across multiple reasoning tasks and found that students trained on full traces matched or approached teacher performance, while students trained on summarized outputs showed no meaningful capability transfer. The gap held across different model sizes and task types, suggesting that the intermediate steps carry information essential to learning the underlying skill.
On reasoning scaffolds
The paper frames the finding as a challenge to efficiency-focused distillation pipelines that compress teacher outputs to save tokens or compute. Summarization discards the reasoning scaffold — the chain of dependencies and sub-goals that a capable model uses to reach an answer. Without that scaffold, the student sees only input-output pairs and defaults to shallow pattern matching rather than learning the decision process.
For practitioners building smaller models from frontier reasoning systems, the implication is direct: distillation budgets that prioritize token count over trace completeness may produce students that parrot answers without acquiring the teacher's problem-solving method. The preprint is available on arXiv (arxiv.org/abs/2606.05988v1).