
DeepSeek open-sources DSpark inference stack with 60–85% speedup
DeepSeek released a full open-source inference acceleration toolkit built around DSpark, the two-stage draft model already running in production for DeepSeek-V4 Flash and Pro.
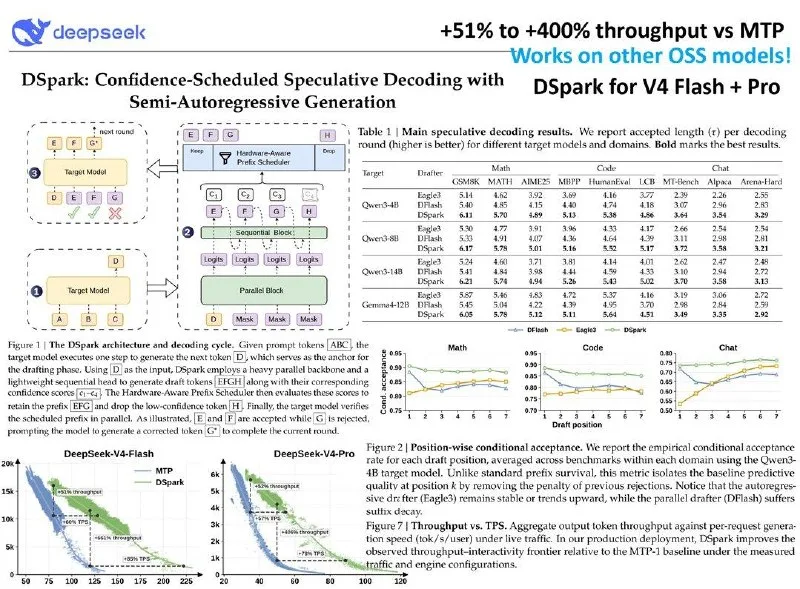
DeepSeek just handed practitioners a complete inference acceleration stack—algorithm, training pipeline, evaluation harness, and data prep—all open-source and production-tested. The centerpiece is DSpark, the draft-model approach the company already runs for DeepSeek-V4 Flash and Pro, where it delivers 60–85 percent faster generation over the prior baseline.
DSpark is a small auxiliary model that writes token drafts for the main LLM to verify. The twist is the two-stage architecture: a parallel token-block generator followed by a lightweight Markov module that refines neighbor dependencies. That design keeps the drafter fast without collapsing quality on long tails. Once the draft is ready, the main model validates it and accepts the correct prefix, rewriting the rest. DSpark dynamically decides how many tokens to send for verification based on per-token confidence and current hardware load.
The result is a minimum 1.5× speedup with no quality loss. Draft-model acceleration is having a moment—Google ships a similar approach for Gemma—but DeepSeek's two-stage design and adaptive batching push the technique further than most public implementations. The entire stack is available on GitHub, including ready-to-run training code, evaluation scripts, and a data pipeline, so teams can reproduce the numbers or adapt the method to their own models.



