
Qwen3-ASR hits state-of-the-art on 30 languages with 2000× throughput at 0.6B
Alibaba's Qwen team released Qwen3-ASR, a 1.7B-parameter multilingual speech recognition model with state-of-the-art accuracy among open systems and 2000× throughput at 0.6B parameters serving 128 concurrent streams across 30 languages and 22 Chinese dialects.
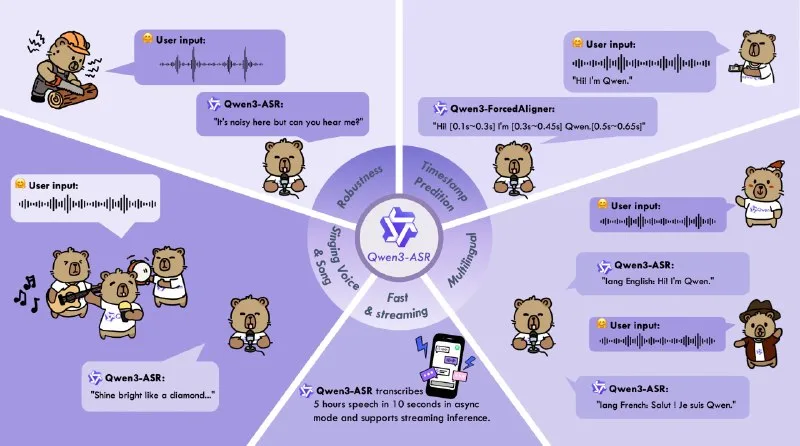
Alibaba's Qwen team released Qwen3-ASR, a 1.7B-parameter multilingual speech recognition model that handles 30 languages, 22 Chinese dialects, and varied accents in a single checkpoint. The model claims state-of-the-art accuracy among open ASR systems and performance comparable to proprietary APIs. It includes native Transformers support, streaming capability, and a unified mode for both real-time and offline transcription, with language identification built into the forward pass—no separate routing logic required.
A smaller 0.6B variant achieves 2000× throughput when serving 128 concurrent requests, making it viable for high-volume production workloads including real-time telephony, live captioning, and edge deployment. The release also ships Qwen3-ForcedAligner-0.6B, a companion model for word-level timestamp alignment supporting 11 languages and audio up to 5 minutes long. Both models run locally under the Qwen open license, which permits commercial use and operates without API constraints.



