Thinking Machines cuts financial triage errors 29.8% with Bridgewater expert labels
Mira Murati's Thinking Machines trained a model on real investor decisions from Bridgewater Associates, achieving 29.8% fewer errors than leading frontier models at 13.8× lower inference cost on financial document triage.
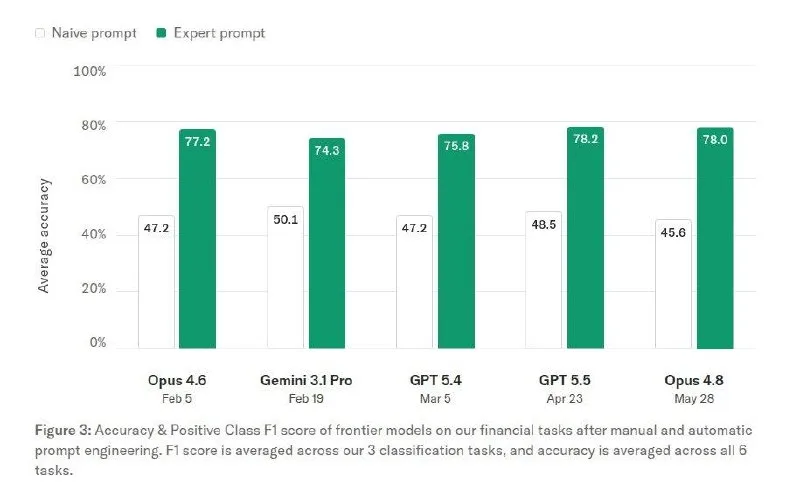
Thinking Machines, the startup Mira Murati launched after leaving OpenAI, released a case study this week showing how Bridgewater Associates turned proprietary investment expertise into training signal for a custom language model. The task was document triage: given financial articles, central bank reports, and analyst letters, predict which pieces an experienced investor should read first. Off-the-shelf prompting delivered 46–50 percent accuracy—barely better than random—while expert-crafted prompts reached 74–78 percent. The real breakthrough came from training on labels supplied by Bridgewater's senior investment team.
The training set included edge cases flagged by the model itself. When the model's ranking diverged from the expert label, Bridgewater analysts reviewed the example a second time to confirm or revise the annotation. That loop filtered out noise and captured the tacit knowledge behind why one tariff headline moves markets while another geopolitical story stays background noise. Thinking Machines mixed task types during fine-tuning, capped gradient updates to prevent overfitting, and distilled outputs from stronger model checkpoints into the training data. The result: 29.8 percent fewer errors than the best frontier model tested, at 13.8× lower inference cost.
The approach scales to any workflow where a small group of specialists makes high-stakes decisions repeatedly—risk review, compliance screening, customer support escalation, research document filtering. The competitive moat is the labeled dataset itself: a competitor cannot download Bridgewater's investment judgment from public sources. Thinking Machines has not disclosed the base model architecture, parameter count, or whether the fine-tuned weights will be released beyond Bridgewater's internal deployment. The open question is whether the accuracy gain holds when the model faces distribution shift—market regimes Bridgewater's historical labels never covered, or document formats the training set didn't include. Watch for Thinking Machines to publish out-of-domain benchmark results and name other enterprise customers running similar fine-tunes.