FlashSVD v1.5 delivers 2.55× decode speedup for SVD-compressed transformers
New inference runtime closes the gap between SVD compression's theoretical savings and real-world serving performance, achieving up to 2.39× end-to-end speedup across popular low-rank families.
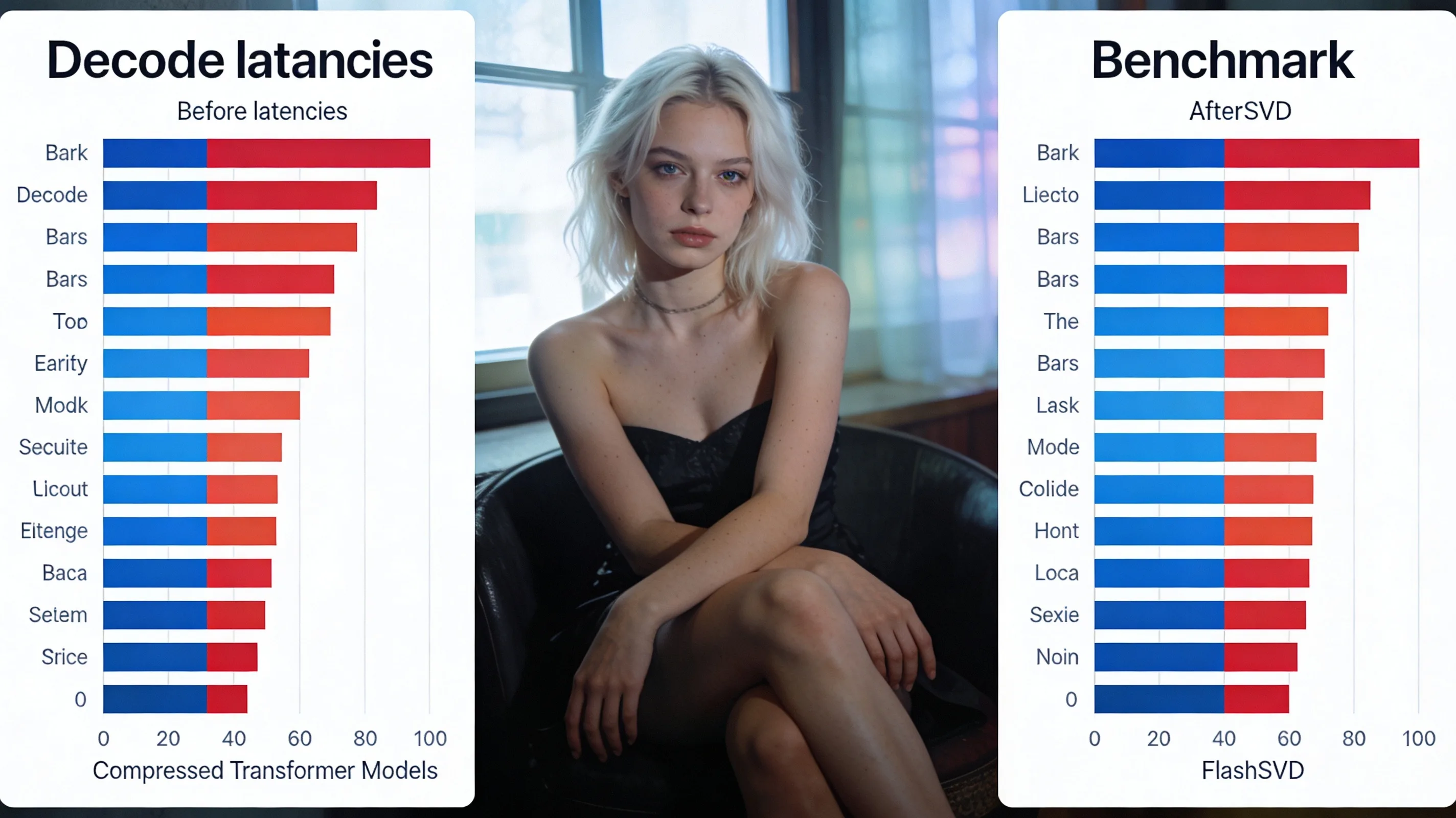
FlashSVD v1.5 is a unified inference runtime that translates SVD-based low-rank compression into actual serving speedups for large language models. The preprint, posted to arXiv on May 12, 2026, addresses a longstanding problem in the open-weight serving ecosystem: while singular value decomposition cuts transformer parameter counts and nominal FLOPs on paper, those savings rarely translate into faster inference in production. The gap stems from a runtime issue rather than a compression flaw—factorized checkpoints fragment execution paths, and the resulting overhead differs substantially between prefill and autoregressive decode phases.
SVD compression has been a popular technique for shrinking open-weight models like Llama, Mistral, and Qwen variants, especially among practitioners running inference on consumer GPUs where memory bandwidth is the bottleneck. The promise is straightforward: decompose weight matrices into smaller factors, serve fewer parameters, run faster. In practice, existing serving stacks treat factorized weights as a series of separate matrix multiplies, which introduces kernel launch overhead, poor cache utilization, and suboptimal scheduling across decode steps. FlashSVD v1.5 attacks that mismatch directly.
The runtime maps diverse public SVD compression families—each with its own checkpoint format and factorization scheme—to a common factorized representation. It then combines phase-specific kernels with dense-KV decode, packed MLP execution, and per-layer CUDA-graph replay to reorganize the low-rank serving path into a thin, optimized runtime. The result is that the theoretical compression savings finally show up in wall-clock time.
Across representative decoder-serving settings, FlashSVD v1.5 achieves up to 2.55× decode speedup and 2.39× end-to-end speedup in the best case. Average gains across multiple popular SVD compression families land at 1.48× decode and 1.44× end-to-end. Those numbers matter for practitioners running local inference at scale: a 1.5× decode speedup halves token latency in chat or agent workloads, and a 2× speedup makes previously marginal hardware viable.
The authors argue that practical low-rank acceleration requires runtime co-design, not compression algorithms alone. The implication is that the next wave of model compression research should ship with inference kernels, not just checkpoint recipes. Code is available at github.com/Zishan-Shao/FlashSVD.