AnyFlow adapts video diffusion to any step count without quality loss
NVIDIA's AnyFlow framework lets video diffusion models generate at arbitrary inference steps while maintaining quality, demonstrated on WAN 2.1 for text-to-video, image-to-video, and video-to-video tasks.
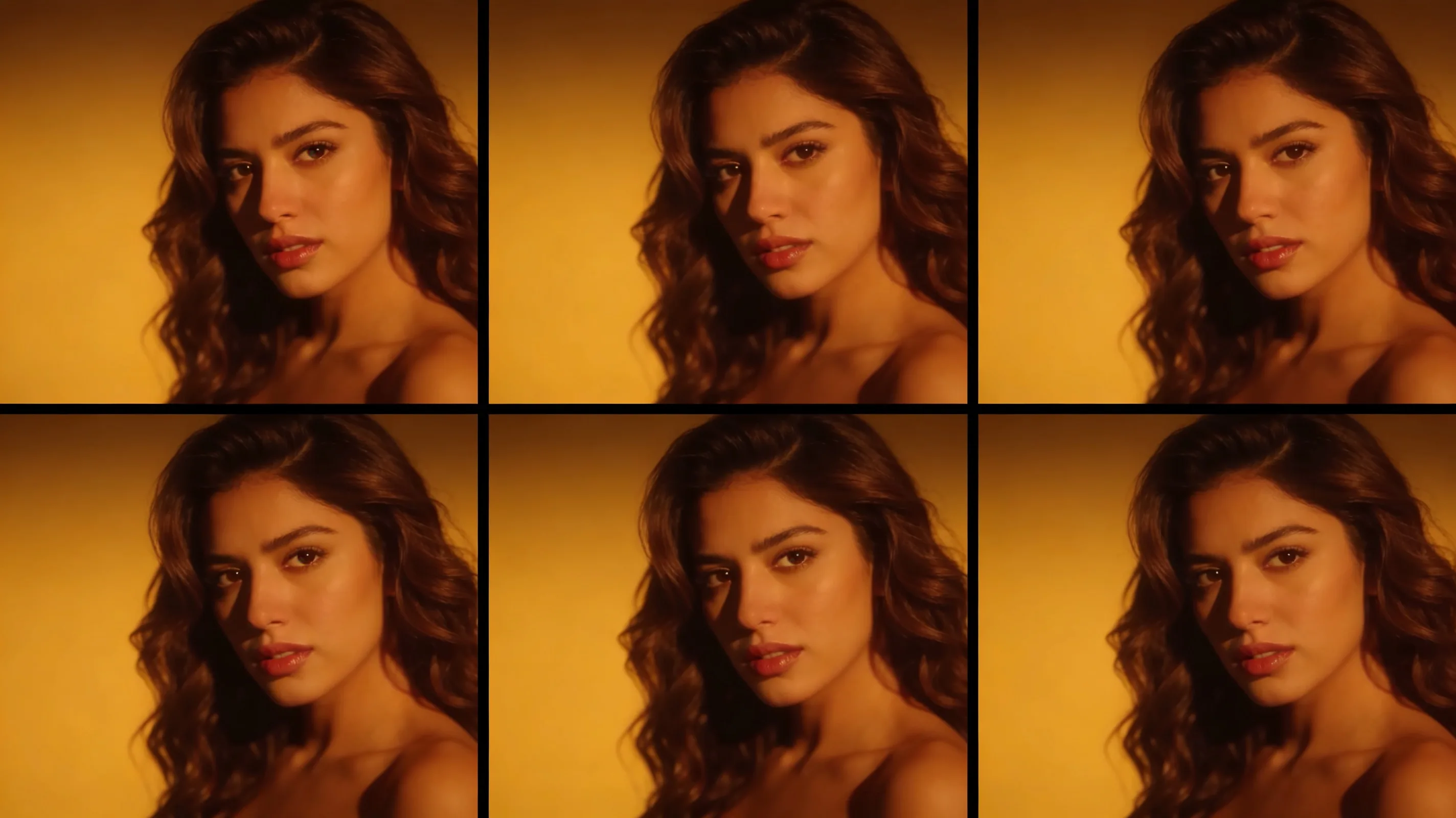
NVIDIA researchers released AnyFlow this week, a framework that lets video diffusion models generate outputs at any number of sampling steps without the quality degradation that typically comes with fewer steps. The technique uses flow maps to dynamically adjust inference, and the team has already integrated it with WAN 2.1, an open-weight video generation model.
AnyFlow addresses a core trade-off in video synthesis: more sampling steps usually mean better quality but slower generation. Most video models are trained for a fixed step count, and deviating from that target—especially downward—tanks output quality. AnyFlow rewires the sampling process so quality scales smoothly with step count, giving practitioners control over the speed-quality curve without retraining.
What stands out
- 01Flow-map scheduling — AnyFlow replaces fixed noise schedules with flow maps that adapt to the chosen step count at inference time. The framework works with both causal (forward-only) and bidirectional video diffusion architectures.
- 02Multi-task unified model — The WAN 2.1 integration handles text-to-video, image-to-video, and video-to-video generation in a single model. Practitioners can switch tasks without swapping weights.
- 03Quality scales with steps — Output quality improves as step count rises, but even low-step runs avoid the artifacts typical of truncated sampling. This makes real-time or near-real-time video generation more practical on consumer hardware.
- 04Open weights and demo — Code, model weights, and a live demo are available on GitHub and HuggingFace. The demo lets users test different step counts and see quality differences firsthand.
- 05