VERDI extracts confidence from LLM judge reasoning without extra inference calls
New method reads verification traces to flag when automated evaluations are trustworthy, hitting 0.72–0.91 AUROC on GPT-4.1-mini without token log-probabilities.
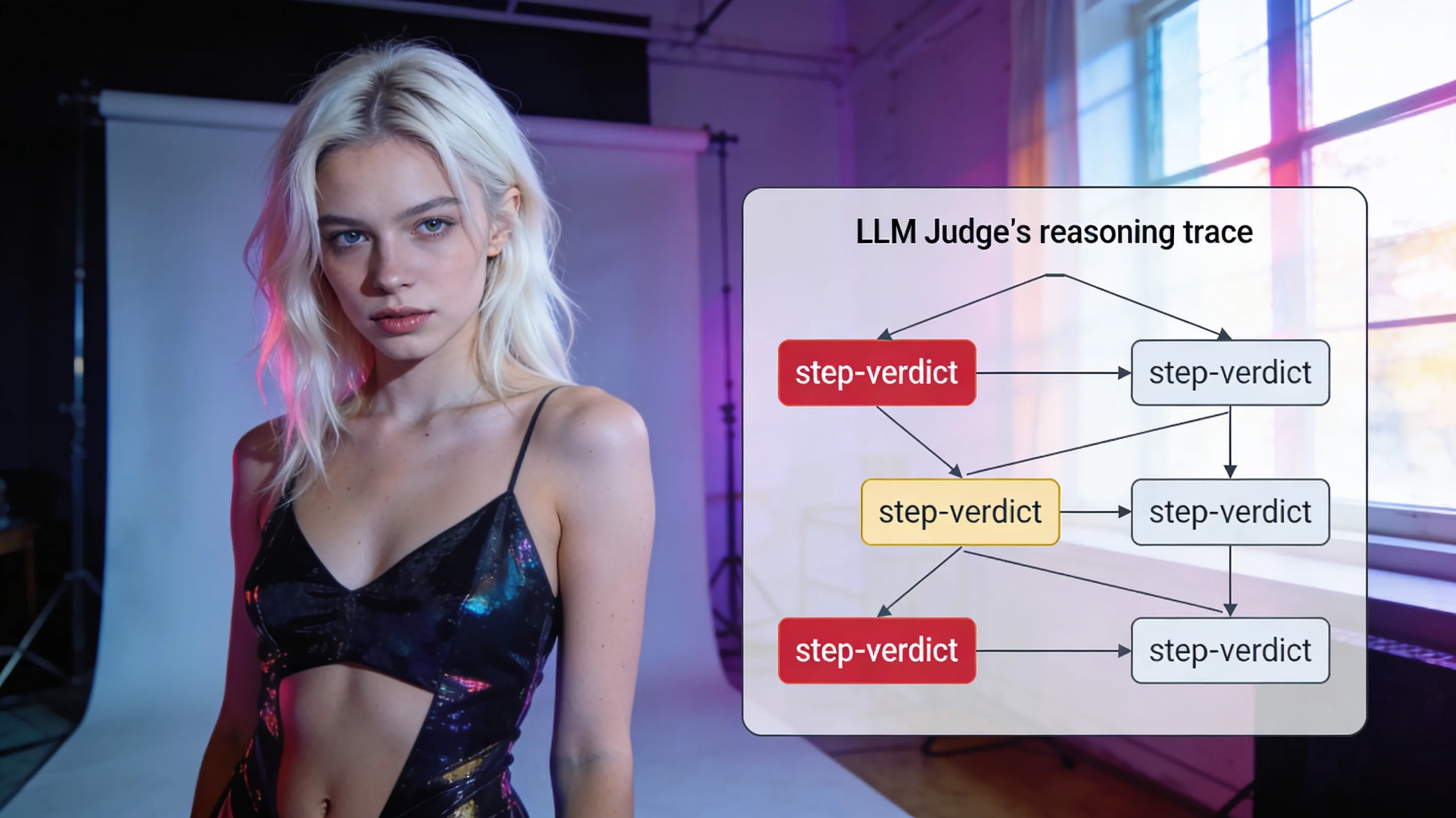
VERDI (VERification-Decomposed Inference) is a confidence-estimation technique that analyzes the reasoning trace a structured LLM judge already produces—no additional inference calls required. The method addresses a persistent gap in LLM-as-Judge deployments: practitioners rarely know when to trust an automated verdict, and the standard fallback—token log-probabilities—either isn't available on commercial APIs or saturates above 0.999 when judges output structured JSON.
The approach decomposes each verification-style evaluation into sub-checks and extracts three signals from the trace: Step-Verdict Alignment (whether intermediate reasoning steps support the final label), Claim-Level Margin (confidence spread across atomic claims), and Evidence Grounding Score (how well cited evidence backs each claim). A Platt-scaled logistic regression combines the signals into a single confidence estimate. Because VERDI reads structure the judge already emits, it adds zero latency and zero cost beyond the original call.
On benchmarks
Across three public datasets, VERDI achieves AUROC between 0.72 and 0.91 on GPT-4.1-mini and 0.66 to 0.80 on GPT-5.4-mini. On open-weight Qwen3.5 models (4B, 9B, 27B parameters), where answer-token log-probabilities are anti-calibrated—higher confidence correlates with errors, yielding AUROC as low as 0.32—VERDI still reaches 0.56 to 0.70. In a production system with eight rubrics, the method hits 0.73 to 0.88 AUROC on factual evaluation tasks. Cross-model transfer experiments show AUROC between 0.66 and 0.69 when a regressor trained on one model is applied to another.
The paper also demonstrates that a 33-million-parameter Natural Language Inference model can replace regex-based extraction of the structural signals, offering a scalable path for practitioners who want to avoid hand-coded parsers. The preprint appeared on arXiv on May 13, 2026.